Analyse von Legacy-Code bei Verlust des Quellcodes: tun oder nicht tun? Anwendung der statischen Analyse in der Softwareentwicklung Frühzeitige Fehlererkennung zur Senkung der Entwicklungskosten
Den Originalartikel finden Sie im Wayback Machine – Internet Archive: Static Code Analysis.
Da alle Artikel auf unserer Seite auf Russisch und Englisch präsentiert werden, haben wir den Artikel Static Code Analysis ins Russische übersetzt. Und gleichzeitig haben wir beschlossen, es auf Habré zu veröffentlichen. Eine Nacherzählung dieses Artikels wurde bereits hier veröffentlicht. Aber ich bin sicher, dass viele daran interessiert sein werden, die Übersetzung zu lesen.
Meiner Meinung nach wichtigste Errungenschaft als Programmierer in den letzten Jahren ist die Bekanntschaft mit der Methode der statischen Codeanalyse und deren aktiver Anwendung. Es geht nicht so sehr um die Hunderte von schwerwiegenden Fehlern, die dank ihr aus dem Code herausgehalten wurden, sondern um die Veränderung, die diese Erfahrung in der Weltanschauung meines Programmierers in Bezug auf Fragen der Zuverlässigkeit und Softwarequalität bewirkt hat.
Es sollte gleich darauf hingewiesen werden, dass nicht alles auf Qualität reduziert werden kann, und dies zuzugeben bedeutet nicht, irgendwelche Ihrer moralischen Prinzipien zu verraten. Wert hat ein Produkt, das Sie als Ganzes erstellen, und die Qualität des Codes ist nur eine seiner Komponenten neben Kosten, Funktionalität und anderen Merkmalen. Die Welt kennt viele supererfolgreiche und respektierte Spielprojekte, die mit Fehlern vollgestopft sind und endlos fallen; und es wäre dumm, ein Spiel mit der gleichen Ernsthaftigkeit zu schreiben, mit der sie Software für Raumfähren entwickeln. Dennoch ist Qualität zweifellos ein wichtiger Bestandteil.
Ich habe immer versucht, guten Code zu schreiben. Von Natur aus bin ich wie ein Handwerker, der von dem Wunsch angetrieben wird, etwas ständig zu verbessern. Ich habe haufenweise Bücher mit langweiligen Kapitelüberschriften wie Strategien, Standards und Qualitätspläne gelesen, und die Arbeit bei Armadillo Aerospace hat mir die Tür zu einer völlig anderen Welt der Softwareentwicklung mit erhöhten Sicherheitsanforderungen geöffnet.
Vor mehr als zehn Jahren, als wir Quake 3 entwickelt haben, habe ich eine Lizenz für PC-Lint gekauft und versucht, es in meiner Arbeit zu verwenden: Die Idee der automatischen Fehlererkennung im Code hat mich gereizt. Die Notwendigkeit, von der Befehlszeile aus zu laufen und lange Listen von Diagnosemeldungen durchzusehen, hielt mich jedoch davon ab, dieses Tool zu verwenden, und ich gab es bald auf.
Seitdem sind sowohl die Anzahl der Programmierer als auch die Größe der Codebasis um eine Größenordnung gewachsen, und der Schwerpunkt der Programmierung hat sich von C nach C++ verlagert. All dies hat einen viel fruchtbareren Boden für Softwarefehler bereitet. Nachdem ich vor einigen Jahren eine Auswahl wissenschaftlicher Artikel zur modernen statischen Codeanalyse gelesen hatte, beschloss ich zu überprüfen, wie sich die Dinge in diesem Bereich in den letzten zehn Jahren verändert haben, seit ich versucht habe, mit PC-Lint zu arbeiten.
Damals wurde unser Code auf der 4. Ebene der Warnungen kompiliert, während wir nur wenige hochspezialisierte Diagnosen deaktiviert ließen. Mit diesem Ansatz, jede Warnung bewusst als Fehler zu behandeln, waren Programmierer gezwungen, sich strikt an diese Richtlinie zu halten. Und obwohl unser Code ein paar staubige Ecken finden konnte, in denen sich im Laufe der Jahre allerlei „Müll“ angesammelt hatte, war er im Allgemeinen recht modern. Wir dachten, wir hätten eine ziemlich gute Codebasis.
Deckung
Alles begann damit, dass ich Coverity kontaktierte und mich für eine Testdiagnose unseres Codes mit ihrem Tool anmeldete. Dies ist ein seriöses Programm, die Kosten einer Lizenz hängen von der Gesamtzahl der Codezeilen ab, und wir haben uns auf einen fünfstelligen Preis geeinigt. Als die Experten von Coverity uns die Ergebnisse der Analyse zeigten, stellten sie fest, dass unsere Datenbank eine der saubersten in ihrer „Gewichtsklasse“ war, die sie je gesehen haben (vielleicht sagen sie das allen Kunden, um sie aufzuheitern), aber das Bericht, den sie uns übergeben haben, enthielt etwa hundert Problemstellen. Dieser Ansatz unterschied sich stark von meiner früheren Erfahrung mit PC-Lint. Der Signal-Rausch-Abstand erwies sich in diesem Fall als extrem hoch: Die meisten Warnungen von Coverity wiesen tatsächlich auf eindeutig fehlerhafte Codeabschnitte hin, die schwerwiegende Folgen haben könnten.Dieser Vorfall öffnete mir buchstäblich die Augen für die statische Analyse, aber der hohe Preis für all das Vergnügen hielt mich einige Zeit davon ab, das Tool zu kaufen. Wir dachten, dass wir im verbleibenden Code vor der Veröffentlichung nicht so viele Fehler haben würden.
Microsoft /analyze
Es ist möglich, dass ich mich letztendlich für den Kauf von Coverity entscheide, aber während ich darüber nachdachte, machte Microsoft meinen Zweifeln ein Ende, indem es eine neue /analyze-Funktion in das 360-SDK implementierte. /Analyze war früher als Komponente der wahnsinnig teuren Top-Version von Visual Studio verfügbar und wurde dann plötzlich für jeden Entwickler auf der Xbox 360 kostenlos. Ich verstehe, dass die Qualität von Spielen auf der Microsoft 360-Plattform höher ist als die Softwarequalität unter Windows. :-)Aus technischer Sicht führt der Microsoft-Analyzer nur eine lokale Analyse durch, d.h. Es ist der globalen Analyse von Coverity unterlegen, aber als wir es einschalteten, fiel es aus die Berge Nachrichten - viel mehr, als Coverity herausgegeben hat. Ja, es gab viele Fehlalarme, aber auch ohne sie gab es viele beängstigende, wirklich gruselige Fehler.
Ich fing langsam an, den Code zu bearbeiten – zuerst kümmerte ich mich um meinen eigenen, dann um den des Systems und schließlich um den des Spiels. Ich musste stoßweise in meiner Freizeit arbeiten, so dass sich der ganze Prozess über ein paar Monate hinzog. Diese Verzögerung hatte jedoch auch einen positiven Nebeneffekt: Wir stellten sicher, dass /analyze tatsächlich wichtige Fehler entdeckte. Tatsache ist, dass unsere Entwickler gleichzeitig mit meinen Änderungen eine große mehrtägige Fehlersuche veranstalteten, und es stellte sich heraus, dass sie jedes Mal die Spur eines Fehlers angriffen, der bereits mit /analyze markiert, aber noch nicht von mir behoben wurde. Darüber hinaus gab es andere, weniger dramatische Fälle, in denen uns das Debuggen zu Code führte, der bereits mit /analyze gekennzeichnet war. Das waren alles echte Fehler.
Am Ende habe ich den gesamten Code, den ich zum Kompilieren in eine ausführbare 360-Datei ohne eine einzige Warnung mit aktiviertem /analyze verwendet habe, und diesen Kompilierungsmodus als Standard für 360-Builds festgelegt. Danach wurde der Code jedes Programmierers, der auf derselben Plattform arbeitete, bei jedem Kompilieren auf Fehler überprüft, sodass er Fehler sofort beheben konnte, wenn sie in das Programm eingeführt wurden, anstatt dass ich mich später darum kümmern musste. Natürlich hat dies die Kompilierung etwas verlangsamt, aber /analyze ist bei weitem das schnellste Tool, das ich je benutzt habe, und glauben Sie mir, es ist es wert.
Einmal haben wir in einem Projekt versehentlich die statische Analyse deaktiviert. Ein paar Monate vergingen, und als ich dies bemerkte und es wieder einschaltete, spuckte das Tool eine Reihe neuer Fehlerwarnungen aus, die in dieser Zeit in den Code eingeführt worden waren. In ähnlicher Weise tragen Programmierer, die nur auf PC oder PS3 arbeiten, fehlerhaften Code zum Repository bei und bleiben im Dunkeln, bis sie eine E-Mail mit einem Bericht über einen „fehlgeschlagenen 360-Build“ erhalten. Diese Beispiele zeigen deutlich, dass Entwickler im Alltag bestimmte Fehler immer wieder machen, und /analyze hat uns zuverlässig vor den meisten davon bewahrt.
PVS-Studio
Da wir /analyze nur auf 360-Code anwenden konnten, war ein großer Teil unserer Codebasis noch immer nicht von der statischen Analyse abgedeckt – dies betraf Code für die PC- und PS3-Plattformen sowie alle Programme, die nur auf dem PC ausgeführt wurden.Das nächste Tool, das ich kennenlernte, war PVS-Studio . Es integriert sich nahtlos in Visual Studio und bietet einen praktischen Demo-Modus (probieren Sie es selbst aus!). Im Vergleich zu /analyze ist PVS-Studio furchtbar langsam, aber es gelang ihm, eine Reihe neuer kritischer Fehler zu finden, selbst in dem Code, der bereits vollständig aus der Sicht von /analyze bereinigt wurde. Neben offensichtlichen Fehlern fängt PVS-Studio viele weitere Mängel ab, die fehlerhafte Programmierklischees sind, auch wenn es auf den ersten Blick wie normaler Code aussieht. Aus diesem Grund ist ein gewisser Prozentsatz an Fehlalarmen fast unvermeidlich, aber verdammt noch mal, solche Muster wurden in unserem Code gefunden, und wir haben sie korrigiert.
Auf der PVS-Studio-Website finden Sie eine große Anzahl großartiger Artikel über das Tool, und viele davon enthalten Beispiele aus echten Open-Source-Projekten, die genau die Arten von Fehlern veranschaulichen, um die es in dem Artikel geht. Ich habe darüber nachgedacht, hier einige indikative Diagnosemeldungen von PVS-Studio einzufügen, aber auf der Website sind bereits viel interessantere Beispiele erschienen. Besuchen Sie also die Seite und überzeugen Sie sich selbst. Und ja – wenn Sie diese Beispiele lesen, schmunzeln Sie nicht und sagen, dass Sie so nie schreiben würden.
PC-Fussel
Am Ende bin ich auf die Option zurückgekommen, PC-Lint in Verbindung mit Visual Lint zu verwenden, um es in die Entwicklungsumgebung zu integrieren. In der legendären Tradition der Unix-Welt kann das Tool so konfiguriert werden, dass es fast jede Aufgabe erfüllt, aber seine Oberfläche ist nicht sehr benutzerfreundlich und Sie können es nicht einfach „aufheben und ausführen“. Ich habe ein Set mit fünf Lizenzen gekauft, aber es war so mühsam, es zu beherrschen, dass, soweit ich weiß, alle anderen Entwickler es schließlich aufgegeben haben. Flexibilität hat ihre Vorteile – zum Beispiel konnte ich es so einrichten, dass unser gesamter Code für die PS3-Plattform getestet wurde, obwohl dies viel Zeit und Mühe gekostet hat.Und wieder wurden neue wichtige Fehler im Code gefunden, der aus Sicht von /analyze und PVS-Studio bereits sauber war. Ich habe ehrlich gesagt versucht, es aufzuräumen, damit die Flusen auch nicht schwören, aber es hat nicht funktioniert. Ich habe den gesamten Systemcode repariert, aber aufgegeben, als ich sah, wie viele Warnungen er dem Spielcode gab. Ich sortierte die Fehler in Klassen und ging die kritischsten an, wobei ich viele andere ignorierte, die eher mit Stilfehlern oder potenziellen Problemen zusammenhängen.
Ich glaube, dass ein Versuch, eine riesige Menge an Code auf das Maximum zu bringen, aus Sicht von PC-Lint offensichtlich zum Scheitern verurteilt ist. Ich habe an Stellen, an denen ich brav versucht habe, jeden lästigen „lint“-Kommentar loszuwerden, einigen Code von Grund auf neu geschrieben, aber für die meisten erfahrenen C/C++-Programmierer ist dieser Ansatz zur Fehlerbehandlung schon zu viel des Guten. Ich muss immer noch mit den PC-Lint-Einstellungen herumspielen, um die am besten geeigneten Warnungen zu finden und das Beste aus dem Tool herauszuholen.
Schlussfolgerungen
Ich habe viel gelernt, als ich das alles durchgemacht habe. Ich fürchte, dass einige meiner Schlussfolgerungen für Leute schwierig sein werden, die nicht in kurzer Zeit persönlich Hunderte von Fehlerberichten durchgehen mussten und sich jedes Mal krank fühlen, wenn sie anfangen, sie zu bearbeiten, und die Standardreaktion auf meine Worte wird sein: " Nun, wir haben - es ist in Ordnung" oder "es ist nicht so schlimm".Der erste Schritt auf diesem Weg besteht darin, sich ehrlich einzugestehen, dass Ihr Code voller Fehler ist. Für die meisten Programmierer ist dies eine bittere Pille, aber ohne sie zu schlucken, werden Sie jeden Vorschlag, den Code zu ändern und zu verbessern, unweigerlich mit Irritation, wenn nicht unverhohlener Feindseligkeit wahrnehmen. Sie müssen wollen kritisiere deinen Code.
Automatisierung ist erforderlich. Wenn Sie Berichte über monströse Fehler in automatischen Systemen sehen, ist es unmöglich, solche Schadenfreude nicht zu erleben, aber für jeden Fehler in der Automatisierung gibt es eine Legion menschlicher Fehler. Rufe nach „besserem Code“, gute Absichten für mehr Code-Review-Sitzungen, Pair Programming und so weiter funktionieren einfach nicht, besonders wenn Dutzende von Menschen an einem Projekt beteiligt sind und die Arbeit in Eile ist. Der große Wert der statischen Analyse liegt in der Möglichkeit jedes Mal, wenn Sie anfangen Finden Sie zumindest kleine Teile von Fehlern, die dieser Technik zugänglich sind.
Mir ist aufgefallen, dass PVS-Studio mit jedem Update dank neuer Diagnosen mehr und mehr Fehler in unserem Code gefunden hat. Daraus können wir schließen, dass die Codebasis, wenn sie eine bestimmte Größe erreicht, alle syntaktisch zulässigen Fehler zu starten scheint. In großen Projekten folgt die Qualität des Codes den gleichen statistischen Mustern wie die physikalischen Eigenschaften von Materie – Mängel sind überall, und Sie können nur versuchen, ihre Auswirkungen auf die Benutzer zu minimieren.
Statische Analysewerkzeuge müssen „mit einer Hand auf dem Rücken gebunden“ arbeiten: Sie müssen auf der Grundlage des Parsens von Sprachen, die nicht unbedingt Informationen für solche Schlussfolgerungen liefern, Schlussfolgerungen ziehen und im Allgemeinen sehr vorsichtige Annahmen treffen. Daher sollten Sie Ihren Parser so weit wie möglich unterstützen – Indexierung der Zeigerarithmetik vorziehen, den Aufrufgraphen in einer einzigen Quelldatei halten, explizite Anmerkungen verwenden und so weiter. Alles, was einem statischen Analysator nicht offensichtlich erscheinen mag, wird mit ziemlicher Sicherheit auch Ihre Programmierkollegen verwirren. Die charakteristische „Hacker“-Abneigung gegen Sprachen mit strenger statischer Typisierung („Bondage and Discipline Languages“) erweist sich in der Tat als kurzsichtig: Die Anforderungen großer, langlebiger Projekte mit großen Programmiererteams unterscheiden sich grundlegend kleine und schnelle Aufgaben, die man selbst erledigt.
Nullzeiger sind zumindest hier das größte Problem in C/C++. Die Möglichkeit der doppelten Verwendung eines einzelnen Werts sowohl als Flag als auch als Adresse führt zu einer unglaublichen Anzahl kritischer Fehler. Daher sollte C++, wann immer möglich, Verweise gegenüber Zeigern bevorzugen. Obwohl eine Referenz „eigentlich“ nichts anderes als derselbe Zeiger ist, unterliegt sie der impliziten Verpflichtung, dass sie nicht null sein kann. Überprüfen Sie Zeiger auf null, wenn sie sich in Referenzen verwandeln – so können Sie dieses Problem später vergessen. Es gibt viele tief verwurzelte und potenziell gefährliche Programmiermuster in der Spieleentwicklung, aber ich kenne keinen Weg, um vollständig und schmerzlos von Nullprüfungen zu Referenzen zu gelangen.
Das zweitwichtigste Problem in unserer Codebasis waren printf-Bugs. Erschwerend kam hinzu, dass die Übergabe von idStr statt idStr::c_str() fast immer mit einem Programmabsturz endete. Als wir jedoch anfingen, /analyze-Anmerkungen für variadische Funktionen zu verwenden, damit die Typüberprüfung korrekt funktioniert, war das Problem ein für alle Mal gelöst. In den nützlichen Warnungen des Analysators sind wir auf Dutzende solcher Fehler gestoßen, die zu einem Absturz führen könnten, wenn eine fehlerhafte Bedingung den entsprechenden Codezweig startet - dies zeigt übrigens auch, wie gering der Prozentsatz unserer Codeabdeckung durch Tests war.
Viele schwerwiegende Fehler, die vom Analysator gemeldet wurden, standen im Zusammenhang mit Codeänderungen, die lange nach dem Schreiben vorgenommen wurden. Ein unglaublich häufiges Beispiel ist, wenn der ideale Code, in dem Zeiger vor der Ausführung einer Operation zuvor auf Null geprüft wurden, später so geändert wurde, dass Zeiger plötzlich ohne Prüfung verwendet wurden. Betrachtet man dieses Problem isoliert, dann könnte man die hohe zyklomatische Komplexität des Codes bemängeln, schaut man sich aber die Historie des Projekts an, stellt sich heraus, dass der Grund eher darin liegt, dass der Autor des Codes dazu nicht in der Lage war dem Programmierer, der später für das Refactoring verantwortlich war, die Prämissen klar übermitteln.
Menschen können sich per Definition nicht auf alles gleichzeitig konzentrieren, konzentrieren Sie sich also zuerst auf den Code, den Sie an Kunden liefern, und achten Sie weniger auf Code für interne Zwecke. Portieren Sie proaktiv Code von einer Vertriebsbasis zu internen Projekten. Kürzlich wurde ein Artikel veröffentlicht, in dem es heißt, dass alle Codequalitätsmetriken in ihrer ganzen Vielfalt fast so perfekt mit der Codegröße korrelieren wie die Fehlerrate, was es ermöglicht, die Anzahl der Fehler mit hoher Genauigkeit aus der Codegröße vorherzusagen allein. Schneiden Sie also den qualitätskritischen Teil Ihres Codes ab.
Wenn Sie sich nicht bis ins Mark vor all den zusätzlichen Schwierigkeiten gefürchtet haben, die die parallele Programmierung mit sich bringt, scheinen Sie sich einfach nicht richtig mit diesem Thema befasst zu haben.
Es ist unmöglich, verlässliche Benchmark-Tests in der Softwareentwicklung durchzuführen, aber unser Erfolg bei der Codeanalyse war so klar, dass ich es mir leisten kann, einfach zu sagen: keine Codeanalyse einzusetzen ist unverantwortlich! Automatisierte Konsolen-Absturzprotokolle enthalten objektive Daten, die deutlich zeigen, dass Rage, obwohl es in vielerlei Hinsicht ein Vorreiter ist, sich als viel stabiler und gesünder als die meisten heutigen Spiele erwiesen hat. Der Start von Rage auf dem PC ist leider gescheitert – ich wette, dass AMD bei der Entwicklung seiner Grafiktreiber keine statische Analyse verwendet.
Hier ist das Rezept für Sie: Wenn Ihre Version von Visual Studio über ein integriertes /analyze verfügt, aktivieren Sie es und versuchen Sie, so zu arbeiten. Wenn ich gebeten würde, eines von vielen Tools auszuwählen, würde ich mich für diese Lösung von Microsoft entscheiden. Allen anderen, die in Visual Studio arbeiten, rate ich, PVS-Studio zumindest im Demo-Modus auszuprobieren. Wenn Sie kommerzielle Software entwickeln, ist der Kauf statischer Analysetools eine der besten Investitionsmöglichkeiten.
Und zum Schluss noch ein Kommentar von Twitter.
Die Verfeinerung von Geschäftsanwendungen globaler Entwickler (CRM, ERP, Abrechnung usw.) unter Berücksichtigung der Merkmale und spezifischen Anforderungen der Arbeitsprozesse des Unternehmens und die Entwicklung eigener Geschäftsanwendungen von Grund auf ist der Standard für russische Unternehmen. Gleichzeitig gibt es bei der Implementierung und dem Betrieb von Geschäftsanwendungen Gefahren für die Informationssicherheit durch Programmierfehler (Pufferüberläufe, nicht initialisierte Variablen usw.) und das Vorhandensein von Funktionen, die dazu führen, dass eingebaute Schutzmechanismen umgangen werden. Solche Funktionen werden in der Phase des Testens und Debuggens der Anwendung eingebaut, aber aufgrund des Fehlens von Code-Sicherheitskontrollverfahren verbleiben sie in der Produktionsversion der Geschäftsanwendung. Außerdem kann nicht garantiert werden, dass Entwickler in der Phase der Erstellung einer Geschäftsanwendung nicht absichtlich zusätzlichen Code einbetten, der zum Vorhandensein nicht deklarierter Funktionen (Software-Lesezeichen) führt.
Die Erfahrung zeigt: Je früher ein Fehler oder ein Lesezeichen in einer Geschäftsanwendung entdeckt wird, desto weniger Ressourcen werden benötigt, um ihn zu beseitigen. Die Komplexität und Kosten der Aufgabe, einen Softwarefehler oder ein Lesezeichen in der Phase des kommerziellen Betriebs einer Geschäftsanwendung zu diagnostizieren und zu beseitigen, sind ungleich höher als die ähnlichen Parameter einer solchen Aufgabe in der Phase des Schreibens des Quellcodes.
ELVIS-PLUS bietet ein Quellcode-Analysesystem basierend auf den Produkten des Weltmarktführers in diesem Bereich — HP Fortify Statischer Code-Analysator (SCA), sowie russische Unternehmen - InfoWatch Appercut und Anwendungsinspektor für positive Technologien.
Ziele der Erstellung des Systems
- Reduzierung des Risikos direkter finanzieller Verluste und Reputationsrisiken durch Angriffe auf Geschäftsanwendungen, die Fehler oder Lesezeichen enthalten.
- Erhöhung des Sicherheitsniveaus des Unternehmensinformationssystems durch Organisation der Kontrolle, Automatisierung und Zentralisierung der Verwaltung der Analyse des Quellcodes von Geschäftsanwendungen.
Vom System gelöste Aufgaben
- Statistische Analyse von Software auf Fehler/Schwachstellen, durchgeführt ohne laufende Anwendungen auf Quellcodeebene.
- Dynamische Analyse von Software auf Fehler/Schwachstellen, durchgeführt nach der Assemblierung und dem Start der Anwendung.
- Implementierung von Technologien zur sicheren Entwicklung von Geschäftsanwendungen während der Erstellung und während des gesamten Lebenszyklus der Anwendung durch Einbettung des Systems in die Anwendungsentwicklungsumgebung.
Architektur und Hauptfunktionen des Systems (am Beispiel des Produkts HP Fortify SCA)
Statische Analyse, auch bekannt als Static Application Security Testing (SAST):
- Identifiziert potenzielle Anwendungsschwachstellen direkt auf Codeebene.
- Hilft bei der Identifizierung von Problemen während des Entwicklungsprozesses.
Dynamische Analyse, auch bekannt als Dynamic Application Security Testing (DAST):
- Erkennt Schwachstellen in laufenden Webanwendungen und Webdiensten durch Simulation vollständiger Angriffsszenarien.
- Überprüft, ob eine bestimmte Schwachstelle in der Praxis ausgenutzt werden kann.
- Beschleunigt die Umsetzung von Korrekturmaßnahmen, indem Sie verstehen, welche Probleme zuerst angegangen werden müssen und warum.
Das auf HP Fortify Software Security Center basierende System ermöglicht es Ihnen, automatisierte Prozesse zum Erkennen, Priorisieren, Beheben, Verfolgen, Überprüfen und Verwalten von Schwachstellen in Unternehmensanwendungssoftware zu implementieren. HP Fortify-Tools können in integrierte Entwicklungsumgebungen (IDE – Integrated Development Environment), Qualitätskontrolltools (QA – Qualitätssicherung) und Fehlerverfolgungssysteme eingebettet werden.

Hauptfunktionen des Systems
- Implementierung und Automatisierung des Prozesses zur Erkennung von Schwachstellen in Anwendungssoftware (ASP) in verschiedenen Phasen der Entwicklung (Erstellung, Debugging, Test, Betrieb, Änderung).
- Erkennung von Schwachstellen in bereitgestellten Webanwendungen in verschiedenen Phasen der Softwareentwicklung (Erstellung, Debugging, Test, Betrieb, Änderung).
- Einrichten von Bedingungen und Kriterien zum Erkennen von Schwachstellen in Anwendungssoftware.
- Unterstützung moderner Programmiersprachen zur Identifizierung von Bedrohungen für die Softwaresicherheit (C/C++, Java, JSP, ASP, .NET, JavaScript, PHP, COBOL, PL/SQL, ABAP, VB6 usw.).
- Unterstützung für verschiedene Entwicklungstools zur Integration in die Anwendungsentwicklungsumgebung.
- Erstellung von Berichten über Sicherheitsprobleme der geprüften Software mit Rangfolge der gefundenen Schwachstellen nach Gefährdungsgrad.
- Senden praktischer Empfehlungen zur Beseitigung erkannter Schwachstellen im Code an die Anwendungsentwicklungsumgebung.
- Aktualisieren der Schwachstellendatenbank, um aktuelle Sicherheitsbedrohungen für Anwendungssoftware basierend auf den vom Anbieter bereitgestellten Informationen zu identifizieren.
Vorteile der Implementierung des Systems
- Reduzierung der Kosten für die Entwicklung, das Testen und die Behebung von Fehlern in Geschäftsanwendungen.
- Reduzierung der Kosten für die Wiederherstellung gehackter Geschäftsanwendungen.
- Verbesserung der Effizienz der Abteilung, die für die Bereitstellung von Informationssicherheit im Unternehmen verantwortlich ist.
Der Begriff wird normalerweise auf Analysen angewendet, die von einer speziellen Software durchgeführt werden, während manuelle Analysen genannt werden Verständnis oder Verständnis Programme.
Je nach verwendetem Tool kann die Analysetiefe von der Bestimmung des Verhaltens einzelner Anweisungen bis hin zu einer Analyse, die den gesamten verfügbaren Quellcode umfasst, variieren. Auch die Art und Weise der Verwendung der bei der Analyse gewonnenen Informationen ist unterschiedlich – von der Identifizierung von Stellen, die möglicherweise Fehler enthalten, bis hin zu formalen Methoden, die einen mathematischen Nachweis jeglicher Eigenschaften des Programms (z. B. Übereinstimmung des Verhaltens mit der Spezifikation) ermöglichen.
Einige Leute betrachten Softwaremetriken und Reverse Engineering als Formen der statischen Analyse.
In letzter Zeit wird die statische Analyse zunehmend bei der Verifizierung der Eigenschaften von Software verwendet, die in hochzuverlässigen Computersystemen verwendet wird.
Die meisten Compiler (wie der GNU C Compiler) zeigen "Warnungen" auf dem Bildschirm an. Warnungen) - Meldungen, dass der Code, da er syntaktisch korrekt ist, höchstwahrscheinlich einen Fehler enthält. Zum Beispiel:
intx; Ganzzahl y = x+ 2 ; // Variable x ist nicht initialisiert!
Dies ist die einfachste statische Analyse. Der Compiler hat viele andere wichtige Eigenschaften - vor allem die Arbeitsgeschwindigkeit und die Qualität des Maschinencodes, sodass Compiler den Code nur auf offensichtliche Fehler überprüfen. Statische Analysatoren sind für eine detailliertere Codeanalyse konzipiert.
Arten von Fehlern, die von statischen Analysatoren erkannt werden
- Undefiniertes Verhalten - nicht initialisierte Variablen, Zugriff auf NULL-Zeiger. Compiler signalisieren auch die einfachsten Fälle.
- Verletzung des Blockdiagramms der Verwendung der Bibliothek. Beispielsweise benötigt jedes fopen fclose . Und wenn die Dateivariable verloren geht, bevor die Datei geschlossen wird, meldet der Analysator möglicherweise einen Fehler.
- Typische Szenarien, die zu undokumentiertem Verhalten führen. Die C-Standardbibliothek ist berüchtigt für ihre vielen technischen Fehler. Einige Funktionen, wie etwa gets , sind von Natur aus unsicher. sprintf und strcpy sind nur unter bestimmten Bedingungen sicher.
- Pufferüberlauf - wenn ein Computerprogramm Daten über die Grenzen eines im Speicher zugewiesenen Puffers hinaus schreibt.
Void doSomething(const char * x) ( char s[ 40 ] ; sprintf (s, "[%s]" , x) ; // sprintf zum lokalen Puffer, Überlauf möglich .... }
- Typische Szenarien, die plattformübergreifende .
Objekt * p = getObject() ; int pNum = reinterpret_cast< int >(p); // true auf x86-32, ein Teil des Zeigers geht auf x64 verloren; brauche size_t
- Fehler in sich wiederholendem Code. Viele Programme führen dasselbe mehrmals mit unterschiedlichen Argumenten aus. Normalerweise werden sich wiederholende Fragmente nicht von Grund auf neu geschrieben, sondern dupliziert und korrigiert.
Ziel.x = Quelle.x + dx; Ziel.y = Quelle.y + dx; // Fehler, brauche dy!
std::wstrings; printf("s ist %s" , s) ;
- Ein unveränderlicher Parameter, der an eine Funktion übergeben wird, ist ein Zeichen für geänderte Anforderungen an das Programm. Einmal war der Parameter aktiviert, aber jetzt wird er nicht mehr benötigt. In diesem Fall kann der Programmierer diesen Parameter komplett loswerden - und die damit verbundene Logik.
doSomething(int n, Bool-Flag) // Flag ist immer wahr( wenn (Flag) ( // etwas Logik) anders ( // Code ist vorhanden, wird aber nicht verwendet) ) doSomething(n, true ) ; ... etwas tun (10 , wahr ); ... etwas tun (x.size() , true ) ;
std::strings; ...s.empty(); // Code tut nichts; du meintest wahrscheinlich s.clear()?
Formale Methoden
Statische Analysewerkzeuge
- Deckung
- lint und lock_lint sind in Sun Studio enthalten
- T-SQL Analyzer ist ein Tool, das Programmmodule in Datenbanken mit Microsoft SQL Server 2005 oder 2008 anzeigen und potenzielle Probleme im Zusammenhang mit schlechter Codequalität erkennen kann.
- AK-VS
siehe auch
- Formale Semantik von PL
- Softwareanalyse
- Allmählicher Abbau
- SPARK-JAP
Anmerkungen
Verknüpfungen
Wikimedia-Stiftung. 2010 .
Sehen Sie in anderen Wörterbüchern, was "Statische Codeanalyse" ist:
- (engl. Dynamic program analysis) Softwareanalyse, die durch Ausführen von Programmen auf einem realen oder virtuellen Prozessor durchgeführt wird (eine Analyse, die ohne laufende Programme durchgeführt wird, wird als statische Codeanalyse bezeichnet). Dienstprogramme ... ... Wikipedia
Die Kontrollflussanalyse ist eine statische Codeanalyse, um die Reihenfolge zu bestimmen, in der ein Programm ausgeführt wird. Die Ausführungsreihenfolge wird als Kontrollflussgraph ausgedrückt. Für viele Sprachen ist der Kontrollflussgraph im Quellcode gut sichtbar ... ... Wikipedia
Dieser Begriff hat andere Bedeutungen, siehe BLAST (Bedeutungen). BLAST Typ Statische Analysewerkzeuge Entwickler Dirk Beyer, Thomas Henzinger, Ranjit Jhala, Rupak Majumdar, Berkeley Betriebssystem Linux, Microsoft Windows ... ... Wikipedia
Die folgenden Tabellen enthalten Softwarepakete, die integrierte Entwicklungstools sind. Separate Compiler und Debugger werden nicht erwähnt. Vielleicht hat der englische Teil aktuellere Informationen. Inhalt 1 ActionScript 2 Ada 3 ... Wikipedia
Debugging ist die Phase der Entwicklung eines Computerprogramms, in der Fehler erkannt, lokalisiert und beseitigt werden. Um zu verstehen, wo der Fehler aufgetreten ist, müssen Sie: die aktuellen Werte der Variablen herausfinden; Finden Sie heraus, welcher Weg eingeschlagen wurde ... ... Wikipedia
Typ Statischer Codeanalysator Entwicklerlabor BiPro Geschrieben in C++ Betriebssystem Plattformübergreifend Schnittstellensprachen Englisch ... Wikipedia
Mit der statischen Analyse können Sie viele verschiedene Fehler und Schwachstellen im Quellcode finden, noch bevor der Code lauffähig ist. Auf der anderen Seite findet die Laufzeitanalyse oder Laufzeitanalyse auf laufender Software statt und erkennt Probleme, sobald sie auftreten, normalerweise unter Verwendung ausgeklügelter Tools. Man könnte argumentieren, dass eine Form der Analyse der anderen vorausgeht, aber Entwickler können beide Methoden kombinieren, um Entwicklungs- und Testprozesse zu beschleunigen und die Qualität des gelieferten Produkts zu verbessern.
Dieser Artikel betrachtet zunächst die Methode der statischen Analyse. Es kann verwendet werden, um Probleme zu verhindern, bevor sie in den Hauptcode eindringen, und sicherzustellen, dass der neue Code dem Standard entspricht. Mithilfe verschiedener Analysetechniken wie Abstract Syntax Tree (AST) und Codepfadanalyse können statische Analysetools versteckte Schwachstellen, logische Fehler, Implementierungsmängel und andere Probleme aufdecken. Dies kann sowohl in der Entwicklungsphase an jedem Arbeitsplatz als auch während der Montage des Systems geschehen. Der Rest des Artikels untersucht eine dynamische Analysemethode, die während der Modulentwicklungs- und Systemintegrationsphase verwendet werden kann und die es Ihnen ermöglicht, Probleme zu identifizieren, die von der statischen Analyse übersehen wurden. Die dynamische Analyse erkennt nicht nur Fehler in Bezug auf Zeiger und andere Unrichtigkeiten, sondern es ist auch möglich, die Nutzung von CPU-Zyklen, RAM, Flash-Speicher und anderen Ressourcen zu optimieren.
Der Artikel diskutiert auch Optionen für die Kombination von statischer und dynamischer Analyse, die dazu beitragen, eine Regression auf frühere Entwicklungsstadien zu verhindern, wenn das Produkt reift. Dieser Dual-Methoden-Ansatz hilft, die meisten Probleme früh in der Entwicklung zu vermeiden, wenn sie am einfachsten und kostengünstigsten zu beheben sind.
Das Beste aus beiden Welten kombinieren
Statische Analysetools finden Fehler früh in einem Projekt, normalerweise bevor die ausführbare Datei erstellt wird. Diese Früherkennung ist besonders nützlich für große Embedded-Systems-Projekte, bei denen Entwickler keine dynamischen Analysetools verwenden können, bis die Software vollständig genug ist, um auf dem Zielsystem ausgeführt zu werden.
In der Phase der statischen Analyse werden Bereiche des Quellcodes mit Schwachstellen entdeckt und beschrieben, darunter versteckte Schwachstellen, logische Fehler, Implementierungsmängel, Fehler bei der Durchführung von Paralleloperationen, selten auftretende Randbedingungen und viele andere Probleme. Beispielsweise führen die statischen Analysetools von Klocwork Insight eine gründliche Analyse des Quellcodes auf syntaktischer und semantischer Ebene durch. Diese Tools führen auch anspruchsvolle interprozedurale Analysen von Kontroll- und Datenflüssen durch und verwenden fortschrittliche Täuschungstechniken, bewerten die Werte, die Variablen annehmen, und modellieren das potenzielle Verhalten des Programms zur Laufzeit.
Entwickler können während der Entwicklungsphase jederzeit statische Analysewerkzeuge verwenden, selbst wenn nur Fragmente des Projekts geschrieben wurden. Je vollständiger der Code ist, desto besser. Mit der statischen Analyse können alle potenziellen Code-Ausführungspfade eingesehen werden – dies kommt beim normalen Testen selten vor, es sei denn, das Projekt erfordert eine 100-prozentige Codeabdeckung. Beispielsweise kann die statische Analyse Programmierfehler erkennen, die mit Randbedingungen oder Pfadfehlern verbunden sind, die zur Entwurfszeit nicht getestet wurden.
Da die statische Analyse versucht, das Verhalten eines Programms anhand eines Quellcodemodells vorherzusagen, wird manchmal ein „Bug“ gefunden, der eigentlich gar nicht existiert – das ist das sogenannte „false positive“ (Falsch-Positiv). Viele moderne statische Analysewerkzeuge implementieren verbesserte Techniken, um dieses Problem zu vermeiden und eine außergewöhnlich genaue Analyse durchzuführen.
| Statische Analyse: Argumente „für“ | Statische Analyse: Argumente dagegen |
| Wird früh im Softwarelebenszyklus verwendet, bevor der Code zur Ausführung bereit ist und bevor das Testen beginnt. Bestehende Codebasen, die bereits getestet wurden, können analysiert werden. Werkzeuge können in die Entwicklungsumgebung als Teil einer Komponente integriert werden, die in "nächtlichen Builds" verwendet wird, und als Teil eines Entwickler-Workbench-Toolkits. Niedrige Kosten: keine Notwendigkeit, Testprogramme oder Stubs zu erstellen; Entwickler können eigene Analysen durchführen. |
Es können Softwarefehler und Schwachstellen entdeckt werden, die nicht unbedingt zum Ausfall des Programms führen oder das Verhalten des Programms während seiner tatsächlichen Ausführung beeinflussen. Nicht-Null-Wahrscheinlichkeit von "falsch positiv". |
Tabelle 1- Argumente „für“ und „gegen“ statische Analyse.
Dynamische Analysetools erkennen Programmierfehler im ausgeführten Code. Gleichzeitig hat der Entwickler die Möglichkeit, das Verhalten der Anwendung während der Ausführung im Idealfall direkt in der Zielumgebung zu beobachten bzw. zu diagnostizieren.
In vielen Fällen modifiziert das dynamische Analysetool den Quell- oder binären Anwendungscode, um Traps oder Hooks für instrumentelle Messungen zu installieren. Diese Hooks können verwendet werden, um Programmfehler zur Laufzeit zu erkennen, die Speichernutzung und Codeabdeckung zu analysieren und andere Bedingungen zu überprüfen. Dynamische Analysewerkzeuge können genaue Informationen über den Zustand des Stacks generieren, wodurch Debugger die Ursache eines Fehlers finden können. Wenn also dynamische Analysetools einen Fehler finden, handelt es sich höchstwahrscheinlich um einen echten Fehler, den der Programmierer schnell identifizieren und beheben kann. Es ist zu beachten, dass zur Erzeugung einer Fehlersituation zur Laufzeit genau die notwendigen Bedingungen vorliegen müssen, unter denen ein Programmfehler auftritt. Dementsprechend müssen Entwickler eine Art Testfall erstellen, um ein bestimmtes Szenario zu implementieren.
| Dynamische Analyse: Argumente „für“ | Dynamische Analyse: Argumente dagegen |
| Seltener „false positives“ – hohe Produktivität bei der Fehlersuche Ein vollständiger Stack- und Laufzeit-Trace kann generiert werden, um die Fehlerursache zu ermitteln. Fehler werden im Kontext eines laufenden Systems sowohl in der realen Welt als auch im Simulationsmodus erfasst. |
Es erfolgt ein Eingriff in das Verhalten des Systems in Echtzeit; der Grad des Eingriffs hängt von der Anzahl der verwendeten Werkzeugeinsätze ab. Dies verursacht nicht immer Probleme, sollte aber bei der Arbeit mit zeitkritischem Code beachtet werden. Die Vollständigkeit der Fehleranalyse hängt vom Grad der Codeabdeckung ab. Somit muss der den Fehler enthaltende Codepfad durchlaufen werden und im Testfall müssen die notwendigen Bedingungen geschaffen werden, um eine Fehlersituation zu erzeugen. |
Tabelle 2- Argumente „für“ und „gegen“ dynamische Analyse.
Frühzeitige Fehlererkennung zur Senkung der Entwicklungskosten
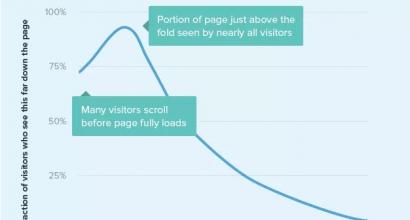
Je früher ein Softwarefehler erkannt wird, desto schneller und günstiger kann dieser behoben werden. Daher sind statische und dynamische Analysewerkzeuge von großem Wert, um Fehler früh im Softwarelebenszyklus zu finden. Verschiedene Studien zu Industrieprodukten zeigen, dass die Behebung eines Problems in der Phase des Testens des Systems (zur Bestätigung der Qualität seiner Arbeit, QA) oder nach der Lieferung des Systems mehrere Größenordnungen teurer ist als die Behebung derselben Probleme der Softwareentwicklungsphase. Viele Organisationen haben ihre eigenen Kostenvoranschläge für die Behebung von Fehlern. Auf Abb. Abbildung 1 zeigt Daten zum diskutierten Problem, entnommen aus dem oft zitierten Buch von Capers Jones. "Angewandte Softwaremessung".
Reis. eines- Im Laufe des Projekts können die Kosten für die Behebung von Softwarefehlern exponentiell ansteigen. Statische und dynamische Analysetools helfen, diese Kosten zu vermeiden, indem sie Fehler früh im Softwarelebenszyklus erkennen.
Statische Analyse
Die statische Analyse ist in der Praxis der Softwareentwicklung fast so lange vorhanden, wie es die Softwareentwicklung selbst gibt. In ihrer ursprünglichen Form wurde die Analyse auf die Überwachung der Einhaltung von Programmierstilstandards (lint) reduziert. Entwickler nutzten es direkt an ihrem Arbeitsplatz. Wenn es um die Erkennung von Fehlern ging, konzentrierten sich frühe statische Analysetools auf das, was an der Oberfläche war: Programmierstil und häufige Syntaxfehler. Selbst die einfachsten statischen Analysetools können beispielsweise einen Fehler wie diesen erkennen:
int foo(int x, int* ptr) ( if(x & 1); ( *ptr = x; return; ) ... )
Hier führt die irrtümliche Verwendung eines zusätzlichen Semikolons zu möglicherweise desaströsen Ergebnissen: Der Eingabeparameterzeiger der Funktion wird unter unerwarteten Bedingungen neu definiert. Der Zeiger wird unabhängig von der geprüften Bedingung immer neu definiert.
Frühe Analysewerkzeuge konzentrierten sich hauptsächlich auf Syntaxfehler. Während ernsthafte Fehler gefunden werden konnten, waren die meisten gefundenen Probleme relativ trivial. Außerdem wurde für die Tools ein ausreichend kleiner Codekontext bereitgestellt, sodass genaue Ergebnisse erwartet werden konnten. Dies lag daran, dass die Arbeit während eines typischen Kompilier-/Verknüpfungszyklus für die Entwicklung erledigt wurde und der Entwickler nur ein kleines Stück Code in einem großen Softwaresystem tat. Ein solches Manko führte dazu, dass die Analysetools auf Schätzungen und Hypothesen basierten, was außerhalb der „Sandbox“ des Entwicklers passieren könnte. Und dies wiederum führte zur Generierung einer erhöhten Anzahl von Meldungen mit „Falsch-Positiven“.
Nachfolgende Generationen statischer Analysewerkzeuge haben sich mit diesen Mängeln befasst und ihre Reichweite über die syntaktische und semantische Analyse hinaus erweitert. In den neuen Werkzeugen wurde eine erweiterte Repräsentation oder ein Modell des generierten Codes gebaut (ähnlich der Kompilierungsphase), und dann wurden alle möglichen Arten der Ausführung des Codes gemäß dem Modell modelliert. Als nächstes wurden logische Flüsse auf diese Pfade abgebildet, mit gleichzeitiger Kontrolle darüber, wie und wo Datenobjekte erstellt, verwendet und zerstört werden. In den Prozess der Analyse von Programmmodulen können Prozeduren zur Analyse von Prozesssteuerung und Datenfluss eingebunden werden. Es minimiert auch "False Positives", indem es neue Ansätze verwendet, um falsche Pfade zu unterbinden, die Werte zu bewerten, die Variablen annehmen können, und potenzielles Verhalten bei der Ausführung in Echtzeit zu modellieren. Um Daten dieses Niveaus in statischen Analysetools zu generieren, ist es notwendig, die gesamte Codebasis des Projekts zu analysieren, ein integrales Systemlayout durchzuführen und nicht nur mit den gewonnenen Ergebnissen in der „Sandbox“ auf dem Desktop des Entwicklers zu arbeiten.
Um diese anspruchsvollen Analyseformen durchzuführen, beschäftigen sich statische Analysewerkzeuge mit zwei Haupttypen von Codeprüfungen:
- Überprüfung des abstrakten Syntaxbaums- um die grundlegende Syntax und Struktur des Codes zu überprüfen.
- Codepfadanalyse- um eine vollständigere Analyse durchzuführen, die davon abhängt, den Zustand von Programmdatenobjekten an einem bestimmten Punkt im Codeausführungspfad zu verstehen.
Abstrakte Syntaxbäume
Ein abstrakter Syntaxbaum ist einfach eine Baumstrukturdarstellung des Quellcodes, wie er in den Vorkompilierungsschritten erzeugt werden könnte. Der Baum enthält eine detaillierte Eins-zu-eins-Zerlegung der Codestruktur, sodass Tools eine einfache Suche nach anomalen Syntaxpunkten durchführen können.
Es ist sehr einfach, einen Checker zu erstellen, der auf Standards bezüglich Namenskonventionen und Funktionsaufrufbeschränkungen prüft, z. B. auf unsichere Bibliotheken. Der Zweck der Durchführung von AST-Prüfungen besteht in der Regel darin, eine Art Rückschluss aus dem Code selbst zu ziehen, ohne zu wissen, wie sich der Code während der Ausführung verhält.
Viele Tools bieten AST-basierte Prüfungen für eine Vielzahl von Sprachen an, einschließlich Open-Source-Tools wie PMD für Java. Einige Werkzeuge verwenden eine X-Pfad-Grammatik oder eine von X-Pfad abgeleitete Grammatik, um Bedingungen zu definieren, die für Steuerprogramme von Interesse sind. Andere Tools bieten erweiterte Mechanismen, mit denen Benutzer ihre eigenen AST-basierten Checker erstellen können. Diese Art der Überprüfung ist relativ einfach durchzuführen, und viele Organisationen erstellen neue Überprüfungsprogramme dieser Art, um die Einhaltung von Codierungsstandards des Unternehmens oder von der Branche empfohlenen Best Practices zu überprüfen.
Codepfadanalyse
Schauen wir uns ein komplexeres Beispiel an. Anstatt nach Fällen von Programmierstilverletzungen zu suchen, wollen wir nun prüfen, ob die versuchte Pointer-Dereferenzierung korrekt funktioniert oder fehlschlägt:
Wenn (x & 1) ptr = NULL; *ptr = 1;
Eine oberflächliche Untersuchung des Fragments führt zu dem offensichtlichen Schluss, dass die Variable ptr NULL sein kann, wenn die Variable x ungerade ist, und diese Bedingung, wenn sie dereferenziert wird, unweigerlich zu einer Nullseite führen wird. Bei der Erstellung eines Testprogramms auf Basis von AST ist das Auffinden eines solchen Programmfehlers jedoch sehr problematisch. Betrachten Sie den AST-Baum (zur Verdeutlichung vereinfacht), der für das obige Code-Snippet generiert würde:
Anweisungsblock If-Anweisung Prüfausdruck Binäroperator & x 1 True-Branch Ausdrucksanweisung Zuweisungsoperator = ptr 0 Ausdrucksanweisung Zuweisungsoperator = Dereferenzierungszeiger - ptr 1 In solchen Fällen keine Baumsuche oder einfache Auflistung von Knoten erkennen nicht in einer einigermaßen verallgemeinerten Form einen Versuch (zumindest manchmal ungültig), den Zeiger ptr zu dereferenzieren. Dementsprechend kann das Parsing-Tool nicht einfach das Syntaxmodell durchsuchen. Es ist auch notwendig, den Lebenszyklus von Datenobjekten zu analysieren, wie sie erscheinen und während der Ausführung innerhalb der Steuerlogik verwendet werden.
Die Codepfadanalyse verfolgt Objekte innerhalb von Ausführungspfaden, sodass Prüfer feststellen können, ob die Daten genau und korrekt verwendet werden. Der Einsatz der Codepfadanalyse erweitert das Spektrum der Fragestellungen, die im Zuge der statischen Analyse beantwortet werden können. Anstatt einfach die Korrektheit des Codes eines Programms zu analysieren, versucht die Codepfadanalyse, die "Absichten" des Codes zu bestimmen und zu überprüfen, ob der Code in Übereinstimmung mit diesen Absichten geschrieben wurde. Diese kann Antworten auf folgende Fragen geben:
- Wurde das neu erstellte Objekt freigegeben, bevor alle Verweise darauf aus dem Geltungsbereich entfernt wurden?
- Wurde der zulässige Wertebereich für einige Datenobjekte überprüft, bevor das Objekt an die OS-Funktion übergeben wird?
- Wurde die Zeichenfolge auf Sonderzeichen geprüft, bevor die Zeichenfolge als SQL-Abfrage übergeben wurde?
- Wird der Kopiervorgang einen Pufferüberlauf verursachen?
- Ist es sicher, diese Funktion zu diesem Zeitpunkt aufzurufen?
Durch die Analyse der Codeausführungspfade auf diese Weise, sowohl vorwärts von der Ereignisauslösung zum Zielskript als auch rückwärts von der Ereignisauslösung zur erforderlichen Dateninitialisierung, kann das Tool Fragen beantworten und einen Fehlerbericht ausgeben, wenn das Zielskript oder die Initialisierungen ausgeführt werden oder nicht wie erwartet ausgeführt.
Die Implementierung einer solchen Fähigkeit ist für die Durchführung einer fortgeschrittenen Quellcodeanalyse unerlässlich. Daher sollten Entwickler nach Tools suchen, die eine erweiterte Codepfadanalyse verwenden, um Speicherlecks, fehlerhafte Zeigerdereferenzen, unsichere oder ungültige Datenübertragungen, Parallelitätsverletzungen und viele andere problematische Bedingungen zu erkennen.
Aktionsfolge beim Durchführen einer statischen Analyse
Die statische Analyse kann Probleme an zwei Schlüsselstellen im Entwicklungsprozess erkennen: beim Schreiben des Programms am Arbeitsplatz und bei der Systemanbindung. Wie bereits erwähnt, arbeitet die aktuelle Generation von Tools hauptsächlich in der Phase der Systemverknüpfung, wenn es möglich ist, den Codestrom des gesamten Systems zu analysieren, was zu sehr genauen Diagnoseergebnissen führt.
Klocwork Insight ist einzigartig in seiner Art und ermöglicht es Ihnen, den am Arbeitsplatz eines bestimmten Entwicklers erstellten Code zu analysieren und gleichzeitig die Probleme zu vermeiden, die mit einer ungenauen Diagnose verbunden sind, die normalerweise für Tools dieser Art charakteristisch ist. Klocwork bietet Connected Desktop Analysis, die den Code eines Entwicklers mit einem Verständnis aller Systemabhängigkeiten analysiert. Dies führt zu einer lokalen Analyse, die genauso genau und leistungsstark ist wie eine zentralisierte Systemanalyse, jedoch noch bevor der Code vollständig zusammengestellt ist.
Aus Sicht der Analysesequenzierung ermöglicht diese Funktion dem Entwickler, sehr früh im Entwicklungslebenszyklus genaue und qualitativ hochwertige statische Analysen durchzuführen. Das Klockwork Insight-Tool meldet alle Probleme an die integrierte Umgebung (IDE) oder die Befehlszeile des Entwicklers, während der Entwickler Code schreibt und regelmäßig kompiliert/verknüpft. Die Ausgabe solcher Nachrichten und Berichte erfolgt, bevor eine dynamische Analyse durchgeführt wird und bevor alle Entwickler ihre Codes zusammenbringen.
Reis. 2- Reihenfolge der Ausführung der statischen Analyse.Dynamische Analysetechnologie
Um Programmierfehler in dynamischen Analysewerkzeugen zu erkennen, werden häufig kleine Codefragmente entweder direkt in den Quellcode des Programms (Einschleusung in den Quellcode) oder in ausführbaren Code (Einschleusung in den Objektcode) eingefügt. In solchen Codesegmenten wird eine "Hygieneprüfung" des Zustands des Programms durchgeführt und ein Fehlerbericht ausgegeben, wenn festgestellt wird, dass etwas nicht korrekt oder nicht funktionsfähig ist. Andere Funktionen können an solchen Tools beteiligt sein, wie z. B. das Verfolgen der Speicherzuweisung und -nutzung im Laufe der Zeit.
Die dynamische Analysetechnologie umfasst:
- Platzierung von Inserts im Quellcode in der Phase der Vorverarbeitung– Ein spezielles Codefragment wird vor der Kompilierung in den Quellcode der Anwendung eingefügt, um Fehler zu erkennen. Dieser Ansatz erfordert keine detaillierten Kenntnisse der Laufzeitumgebung, weshalb diese Methode bei Test- und Analysetools für eingebettete Systeme beliebt ist. Ein Beispiel für ein solches Tool ist das Produkt IBM Rational Test RealTime.
- Platzieren von Inserts im Objektcode– für ein solches dynamisches Analysetool müssen Sie über ausreichende Kenntnisse der Laufzeitumgebung verfügen, um Code direkt in ausführbare Dateien und Bibliotheken einfügen zu können. Bei diesem Ansatz müssen Sie nicht auf den Quellcode des Programms zugreifen oder die Anwendung neu verknüpfen. Ein Beispiel für ein solches Tool ist IBM Rational Purify.
- Einfügen von Code zur Kompilierzeit– Der Entwickler verwendet spezielle Schlüssel (Optionen) des Compilers zur Einbindung in den Quellcode. Dabei wird die Fähigkeit des Compilers zur Fehlererkennung genutzt. Beispielsweise verwendet der GNU C/C++ 4.x-Compiler die Mudflap-Technologie, um Probleme mit Zeigeroperationen zu erkennen.
- Spezialisierte Laufzeitbibliotheken– Um Fehler in den übergebenen Parametern zu erkennen, verwendet der Entwickler Debug-Versionen von Systembibliotheken. Funktionen wie strcpy() sind berüchtigt wegen der Möglichkeit von Null- oder fehlerhaften Zeigern zur Laufzeit. Bei der Verwendung von Debug-Versionen von Bibliotheken werden solche "schlechten" Parameter erkannt. Diese Technologie erfordert kein erneutes Verknüpfen der Anwendung und beeinträchtigt die Leistung in geringerem Maße als die vollständige Verwendung von Einfügungen im Quell-/Objektcode. Diese Technologie wird im RAM-Analysetool in der QNX® Momentics® IDE verwendet.
In diesem Artikel betrachten wir die Technologien, die in den Entwicklertools von QNX Momentics verwendet werden, mit besonderem Schwerpunkt auf GCC Mudflap und spezialisierten Laufzeitbibliotheken.
GNU C/C++ Mudflap: Kompilierzeit-Injektion in den Quellcode
Das Mudflap-Tool, das in Version 4.x des GNU C/C++ Compilers (GCC) enthalten ist, verwendet Kompilierzeit-Injektion in den Quellcode. Gleichzeitig werden während der Ausführung Strukturen überprüft, die potenziell Fehler enthalten. Der Schwerpunkt von Mudflap liegt auf Zeigeroperationen, da sie die Quelle vieler Laufzeitfehler für in C und C++ geschriebene Programme sind.
Mit der Einbeziehung von Mudflap hat der GCC-Compiler einen weiteren Durchlauf, wenn er den Verifizierungscode für Zeigeroperationen einfügt. Der eingefügte Code führt normalerweise eine Validierung der Werte der übergebenen Zeiger durch. Falsche Zeigerwerte führen dazu, dass GCC Meldungen an das Standard-Fehlerausgabegerät der Konsole (stderr) ausgibt. Der Zeigerprüfer von Mudflap überprüft nicht nur Zeiger auf Null: Seine Datenbank speichert Speicheradressen für tatsächliche Objekte und Objekteigenschaften, wie z. Mit einer solchen Datenbank können Sie schnell die erforderlichen Daten erhalten, wenn Sie Speicherzugriffsvorgänge im Quellcode des Programms analysieren.
Bibliotheksfunktionen wie strcpy() überprüfen keine übergebenen Parameter. Solche Funktionen werden auch nicht von Mudflap getestet. In Mudflap ist es jedoch möglich, einen Symbol-Wrapper für statisch verknüpfte Bibliotheken oder eine Einfügung für dynamische Bibliotheken zu erstellen. Mit dieser Technologie wird zwischen der Anwendung und der Bibliothek eine zusätzliche Schicht geschaffen, die es ermöglicht, die Parameter zu validieren und eine Meldung über das Auftreten von Abweichungen auszugeben. Mudflap verwendet einen heuristischen Algorithmus, der auf der Kenntnis der von der Anwendung verwendeten Speichergrenzen (Heap, Stack, Code- und Datensegmente usw.) basiert, um zu bestimmen, ob die zurückgegebenen Zeigerwerte gültig sind.
Mithilfe der Befehlszeilenoptionen des GCC-Compilers kann ein Entwickler Mudflap-Funktionen zum Einfügen von Codefragmenten und zum Steuern des Verhaltens aktivieren, z. B. das Verwalten von Verstößen (Grenzen, Werte), das Durchführen zusätzlicher Überprüfungen und Einstellungen, das Aktivieren von Heuristik und Selbstdiagnose. Beispielsweise legt der Schalter -fmudflap die standardmäßige Mudflap-Konfiguration fest. Compiler-Meldungen über von Mudflap gefundene Verstöße werden auf der Ausgabekonsole (stderr) oder auf der Kommandozeile ausgegeben. Die ausführliche Ausgabe enthält Informationen über die Verletzung und die beteiligten Variablen und Funktionen sowie den Speicherort des Codes. Diese Informationen können automatisch in die IDE importiert werden, wo sie gerendert und gestackt werden. Anhand dieser Daten kann der Entwickler schnell an die entsprechende Stelle im Quellcode des Programms navigieren.
Auf Abb. Abbildung 3 zeigt ein Beispiel dafür, wie ein Fehler in der IDE zusammen mit den entsprechenden Backtrace-Informationen dargestellt wird. Der Backtrace fungiert als Link zum Quellcode, sodass der Entwickler die Ursache des Problems schnell diagnostizieren kann.
Die Verwendung von Mudflap kann die Verbindungszeit erhöhen und die Leistung zur Laufzeit verringern. Die im Artikel „Mudflap: Pointer Use Checking for C/C++“ präsentierten Daten deuten darauf hin, dass sich bei aktiviertem Mudflap die Verbindungszeit um das 3- bis 5-fache erhöht und das Programm um den Faktor 1,25 bis 5 langsamer läuft. Es ist klar dass Entwickler zeitkritischer Anwendungen diese Funktion mit Vorsicht verwenden sollten. Nichtsdestotrotz ist Mudflap ein leistungsstarkes Tool zur Identifizierung fehleranfälliger und potenziell fataler Codekonstrukte. QNX plant, Mudflap in zukünftigen Versionen seiner dynamischen Analysetools einzusetzen.

Reis. 3- Verwenden der in der QNX Momentics IDE angezeigten Backtrace-Informationen, um den Quellcode zu finden, der den Fehler verursacht hat.
Debuggen Sie Versionen von Laufzeitbibliotheken
Neben der Verwendung spezieller Debugging-Inserts in den Laufzeitbibliotheken, die zu erheblichen zusätzlichen Speicher- und Zeitkosten in der Link- und Laufzeitphase führen, können Entwickler auf vorinstrumentierte Laufzeitbibliotheken zurückgreifen. In solchen Bibliotheken wird um die Funktionsaufrufe Code hinzugefügt, dessen Zweck es ist, die Gültigkeit der Eingabeparameter zu überprüfen. Betrachten Sie zum Beispiel einen alten Freund, die Funktion zum Kopieren von Zeichenfolgen:
strcpy(a,b);
Es benötigt zwei Parameter, die beide Zeiger auf einen Typ sind verkohlen: eine für die ursprüngliche Zeichenfolge ( b) und eine weitere für die Ergebniszeichenfolge ( a). Trotz dieser Einfachheit kann diese Funktion eine Quelle vieler Fehler sein:
- wenn Zeigerwert a null oder ungültig ist, dann führt das Kopieren zu diesem Ziel zu einem Speicherzugriff verweigert-Fehler;
- wenn Zeigerwert b null oder ungültig ist, dann führt das Lesen von Informationen von dieser Adresse zu einem Speicherzugriff verweigert-Fehler;
- wenn am Ende der Zeile b wenn das abschließende Zeichen „0“ fehlt, werden mehr Zeichen als erwartet in die Zielzeichenfolge kopiert;
- wenn die Saitengröße b mehr als der für die Zeichenfolge zugewiesene Speicher a, dann werden mehr Bytes als erwartet an die angegebene Adresse geschrieben (ein typisches Pufferüberlaufszenario).
Die Debug-Version der Bibliothek prüft die Parameterwerte‘ a' und ' b'. Auch die Saitenlängen werden auf Kompatibilität geprüft. Wird ein ungültiger Parameter gefunden, wird eine entsprechende Alarmmeldung ausgegeben. In der QNX Momentics Umgebung werden diese Fehlermeldungen aus dem Zielsystem importiert und auf dem Bildschirm angezeigt. Die QNX Momentics-Umgebung verwendet auch Speicherzuweisungs- und Freigabe-Tracking-Technologie, um eine gründliche Analyse der RAM-Nutzung zu ermöglichen.
Die Debug-Version der Bibliothek funktioniert mit jeder Anwendung, die ihre Funktionen verwendet; Sie müssen keine weiteren Änderungen am Code vornehmen. Darüber hinaus kann der Entwickler die Bibliothek während des Anwendungsstarts hinzufügen. Die Bibliothek ersetzt dann die entsprechenden Teile der vollständigen Standardbibliothek, sodass keine Debug-Version der vollständigen Bibliothek verwendet werden muss. In der QNX Momentics IDE kann ein Entwickler eine solche Bibliothek beim Programmstart als Teil einer normalen interaktiven Debug-Sitzung hinzufügen. Auf Abb. Abbildung 4 zeigt ein Beispiel dafür, wie QNX Momentics Speicherfehler erkennt und meldet.
Die Debug-Versionen der Bibliotheken bieten eine bewährte „nicht aggressive“ Methode zur Erkennung von Fehlern beim Aufruf von Bibliotheksfunktionen. Diese Technik ist ideal für die RAM-Analyse und andere Analysemethoden, die auf übereinstimmende Aufrufpaare angewiesen sind, wie beispielsweise malloc() und free(). Mit anderen Worten, diese Technologie kann nur Laufzeitfehler für Code mit Bibliotheksaufrufen erkennen. Es erkennt viele typische Fehler nicht, wie z. B. Inline-Zeiger-Dereferenzierungen oder falsche Zeigerarithmetik. Typischerweise wird beim Debuggen nur eine Teilmenge der Systemaufrufe überwacht. Mehr dazu erfahren Sie im Artikel.

Reis. vier- Die RAM-Analyse erfolgt durch Platzieren von Traps im Bereich der API-Aufrufe im Zusammenhang mit dem Speicherzugriff.
Aktionsfolge in der dynamischen Analyse
Kurz gesagt umfasst die dynamische Analyse das Erfassen von Verletzungsereignissen oder anderen wichtigen Ereignissen im eingebetteten Zielsystem, das Importieren dieser Informationen in die Entwicklungsumgebung und die anschließende Verwendung von Visualisierungstools, um fehlerhafte Codeabschnitte schnell zu identifizieren.
Wie in Abb. 5 ermöglicht die dynamische Analyse nicht nur das Erkennen von Fehlern, sondern hilft auch, die Aufmerksamkeit des Entwicklers auf die Details des Speicherverbrauchs, der CPU-Zyklen, des Speicherplatzes und anderer Ressourcen zu lenken. Der Analyseprozess besteht aus mehreren Schritten, und ein gutes dynamisches Analysetool bietet eine starke Unterstützung für jeden Schritt:
- Überwachung- Zunächst erfasst es Laufzeitfehler, erkennt Speicherlecks und zeigt alle Ergebnisse in der IDE an.
- Einstellung- dann hat der Entwickler die Möglichkeit, jeden Fehler bis zur störenden Source-Zeile zurückzuverfolgen. Bei guter Integration in die IDE wird jeder Fehler auf dem Bildschirm angezeigt. Der Entwickler muss einfach auf die Zeile des Fehlers klicken, und das Quellcodefragment wird mit der Zeile geöffnet, die die Arbeit unterbricht. In vielen Fällen kann ein Entwickler ein Problem schnell beheben, indem er den verfügbaren Stack-Trace und zusätzliche Quellcode-Tools in der IDE (Funktionsaufruf-Viewer, Call-Tracer usw.) verwendet.
- Profilierung– Durch die Behebung erkannter Fehler und Speicherlecks kann der Entwickler die Ressourcennutzung im Laufe der Zeit analysieren, einschließlich Spitzen, Lastdurchschnitte und Ressourcenüberschreitungen. Im Idealfall bietet das Analysetool eine visuelle Darstellung der langfristigen Ressourcennutzung, sodass Sie Spitzen bei der Speicherzuweisung und andere Anomalien sofort erkennen können.
- Optimierung– Mit den Informationen der Profiling-Phase kann der Entwickler nun eine „feine“ Analyse der Ressourcennutzung des Programms durchführen. Unter anderem können solche Optimierungen Ressourcenspitzen und Ressourcen-Overheads, einschließlich RAM- und CPU-Auslastung, minimieren.

Reis. 5- Typischer Handlungsablauf für die dynamische Analyse
Kombinieren der Handlungsabläufe verschiedener Analysearten in der Entwicklungsumgebung
Jedes der statischen und dynamischen Analysewerkzeuge hat seine eigenen Stärken. Dementsprechend sollten Entwicklungsteams diese Tools gemeinsam verwenden. Beispielsweise sind statische Analysewerkzeuge in der Lage, Fehler zu erkennen, die von dynamischen Analysewerkzeugen übersehen werden, da dynamische Analysewerkzeuge nur dann einen Fehler abfangen, wenn das fehlerhafte Stück Code während des Tests ausgeführt wird. Andererseits erkennen dynamische Analysetools Softwarefehler im letzten laufenden Prozess. Eine Diskussion über den Fehler ist kaum nötig, wenn die Verwendung eines Nullzeigers bereits entdeckt wurde.
Idealerweise verwendet ein Entwickler beide Analysewerkzeuge in seiner täglichen Arbeit. Die Aufgabe wird erheblich erleichtert, wenn die Tools gut in die Entwicklungsumgebung am Arbeitsplatz integriert sind.
Hier ein Beispiel für die gemeinsame Nutzung zweier Arten von Werkzeugen:
- Zu Beginn des Arbeitstages sieht sich der Entwickler den Bericht über die Ergebnisse des nächtlichen Builds an. Dieser Bericht enthält sowohl die Build-Fehler selbst als auch die Ergebnisse der statischen Analyse, die während des Builds durchgeführt wurde.
- Der statische Analysebericht listet die erkannten Fehler zusammen mit Informationen auf, die Ihnen bei der Behebung helfen, einschließlich Links zum Quellcode. Mithilfe der IDE kann der Entwickler jede Situation entweder als echten Fehler oder als „falsch positiv“ markieren. Danach werden die tatsächlich vorhandenen Fehler korrigiert.
- Der Entwickler speichert die lokal vorgenommenen Änderungen in der IDE zusammen mit allen neuen Codeausschnitten. Der Entwickler überträgt diese Änderungen nicht zurück an das Quellcodeverwaltungssystem, bis die Änderungen überprüft und getestet wurden.
- Der Entwickler analysiert und korrigiert den neuen Code mit einem statischen Analysetool am lokalen Arbeitsplatz. Um eine qualitativ hochwertige Fehlererkennung und das Fehlen von „false positives“ zu gewährleisten, nutzt die Analyse erweiterte Informationen auf Systemebene. Diese Informationen stammen aus dem nächtlichen Erstellungs-/Analyseprozess.
- Nach der Analyse und „Bereinigung“ von neuem Code baut der Entwickler den Code in ein lokales Testabbild oder eine ausführbare Datei ein.
- Mithilfe dynamischer Analysetools führt der Entwickler Tests durch, um die vorgenommenen Änderungen zu überprüfen.
- Mithilfe der IDE kann der Entwickler Fehler, die über die dynamischen Analysetools gemeldet werden, schnell identifizieren und beheben. Der Code gilt als endgültig und einsatzbereit, wenn er die statische Analyse, Komponententests und dynamische Analyse durchlaufen hat.
- Der Entwickler übermittelt Änderungen an das Quellcodeverwaltungssystem; Danach nimmt der modifizierte Code am anschließenden nächtlichen Verknüpfungsprozess teil.
Dieser Workflow ähnelt dem von mittleren bis großen Projekten, die bereits nächtliche Builds, Quellcodeverwaltung und Codebesitz verwenden. Da die Tools in die IDE integriert sind, können Entwickler schnell statische und dynamische Analysen durchführen, ohne vom typischen Arbeitsablauf abzuweichen. Dadurch steigt die Qualität des Codes bereits bei der Quellcode-Erstellung deutlich an.
Die Rolle der RTOS-Architektur
Im Rahmen der Diskussion um statische und dynamische Analysewerkzeuge mag die Erwähnung der RTOS-Architektur unangebracht erscheinen. Aber es stellt sich heraus, dass ein gut gebautes RTOS die Erkennung, Lokalisierung und Behebung vieler Softwarefehler erheblich erleichtern kann.
Beispielsweise befinden sich in einem Mikrokernel-RTOS wie QNX Neutrino alle Anwendungen, Gerätetreiber, Dateisysteme und Netzwerkstacks außerhalb des Kernels in separaten Adressräumen. Dadurch sind sie alle vom Zellkern und voneinander isoliert. Dieser Ansatz bietet den höchsten Grad an Fehlerlokalisierung: Der Ausfall einer der Komponenten führt nicht zum Zusammenbruch des Gesamtsystems. Darüber hinaus stellt sich heraus, dass es einfach ist, einen RAM-bezogenen Fehler oder einen anderen logischen Fehler auf die genaue Komponente zu isolieren, die diesen Fehler verursacht hat.
Wenn beispielsweise ein Gerätetreiber versucht, auf Speicher außerhalb seines Prozesscontainers zuzugreifen, kann das Betriebssystem den Prozess identifizieren, den Ort des Fehlers angeben und eine Speicherauszugsdatei generieren, die von Quellcode-Debuggern angezeigt werden kann. Gleichzeitig funktioniert der Rest des Systems weiter und der Entwickler kann das Problem lokalisieren und an der Behebung arbeiten.

Reis. 6- In einem Mikrokernel-Betriebssystem führen Fehler im RAM für Treiber, Protokollstapel und andere Dienste nicht zu einer Unterbrechung anderer Prozesse oder des Kernels. Darüber hinaus kann das Betriebssystem einen nicht autorisierten Versuch, auf den Speicher zuzugreifen, sofort erkennen und angeben, von welchem Code dieser Versuch unternommen wurde.
Im Vergleich zu einem herkömmlichen OS-Kernel hat der Mikrokernel eine ungewöhnlich kurze Mean Time to Repair (MTTR) nach einem Ausfall. Überlegen Sie, was passiert, wenn ein Gerätetreiber abstürzt: Das Betriebssystem kann den Treiber herunterfahren, die vom Treiber verwendeten Ressourcen wiederherstellen und den Treiber neu starten. Dies dauert normalerweise einige Millisekunden. In einem typischen monolithischen Betriebssystem muss das Gerät neu gestartet werden – dieser Vorgang kann einige Sekunden bis mehrere Minuten dauern.
Schlussbemerkungen
Statische Analysetools können Programmierfehler erkennen, noch bevor der Code ausgeführt wird. Es werden sogar solche Fehler gefunden, die beim Blocktest, Systemtest und auch bei der Integration nicht erkannt werden, da es sehr schwierig ist, eine vollständige Codeabdeckung für komplexe Anwendungen bereitzustellen, und dies mit erheblichen Kosten verbunden ist. Darüber hinaus können Entwicklungsteams während regelmäßiger Systemaufbauten statische Analysetools verwenden, um sicherzustellen, dass jedes Stück neuen Codes analysiert wird.
Währenddessen unterstützen dynamische Analysewerkzeuge die Integrations- und Testphasen, indem sie Fehler (oder potenzielle Probleme), die während der Programmausführung auftreten, an die Entwicklungsumgebung melden. Diese Tools bieten auch eine vollständige Rückverfolgung bis zum Auftreten des Fehlers. Mithilfe dieser Informationen können Entwickler mysteriöse Programmfehler oder Systemabstürze in viel kürzerer Zeit postmortem debuggen. Eine dynamische Analyse durch Stack-Traces und Variablen kann die zugrunde liegenden Ursachen des Problems aufdecken – dies ist besser, als überall „if (ptr != NULL)“-Anweisungen zu verwenden, um Abstürze zu verhindern und zu umgehen.
Der Einsatz von Früherkennung, besserer und vollständiger Codetestabdeckung sowie Fehlerkorrektur hilft Entwicklern, qualitativ hochwertigere Software in kürzerer Zeit zu erstellen.
Literaturverzeichnis
- Eigler, Frank Ch., „Mudflap: Pointer Use Checking for C/C++“, Proceedings of the GCC Developers Summit 2003, pg. 57-70. http://www.linux.org.uk/~ajh/gcc/gccsummit-2003-proceedings.pdf
- „Heap Analysis: Making Memory Errors a Thing of the Past“, QNX Neutrino RTOS Programmer’s Guide. http://pegasus.ott.qnx.com/download/download/16853/neutrino_prog.pdf
Über QNX Softwaresysteme
QNX Software Systems ist eine Tochtergesellschaft von Harman International und ein weltweit führender Anbieter innovativer Technologien für eingebettete Systeme, darunter Middleware, Entwicklungstools und Betriebssysteme. Das QNX® Neutrino® RTOS, QNX Momentics® Development Kit und QNX Aviage® Middleware, basierend auf einer modularen Architektur, bilden die robusteste und skalierbarste Software-Suite für den Aufbau leistungsstarker eingebetteter Systeme. Führende globale Unternehmen wie Cisco, Daimler, General Electric, Lockheed Martin und Siemens setzen QNX-Technologien in großem Umfang in Netzwerkroutern, medizinischen Geräten, Fahrzeugtelematikeinheiten, Sicherheitssystemen, Industrierobotern und anderen kritischen und unternehmenskritischen Anwendungen ein. Aufgaben. Der Hauptsitz des Unternehmens befindet sich in Ottawa (Kanada), und Produkthändler befinden sich in mehr als 100 Ländern auf der ganzen Welt.
Über Klocwork
Die Produkte von Klocwork sind für die automatisierte Analyse von statischem Code, die Erkennung und Vermeidung von Softwarefehlern und Sicherheitsproblemen konzipiert. Unsere Produkte bieten Entwicklungsteams die Werkzeuge, um die Ursachen von Softwarequalitäts- und Sicherheitsmängeln zu identifizieren und diese Mängel während des gesamten Entwicklungsprozesses zu verfolgen und zu verhindern. Die patentierte Technologie von Klocwork wurde 1996 eingeführt und hat für mehr als 80 Kunden, von denen viele Fortune-500-Unternehmen sind und die weltweit begehrtesten Softwareentwicklungsumgebungen anbieten, eine hohe Kapitalrendite (ROI) erzielt. Klocwork ist ein privat geführtes Unternehmen mit Niederlassungen in Burlington, San Jose, Chicago, Dallas (USA) und Ottawa (Kanada).